InfoDesk/Science
역전파(Backpropagation) 알고리즘의 유래 및 이론(수학x) 설명
inhae
2025. 8. 22. 06:30
출처 : ChatGPT
역전파 알고리즘(backpropagation)은 인공신경망(artificial neural networks)의 학습 문제를 해결하는 핵심 알고리즘으로, 1980년대에 재조명되면서 연결주의(신경망 기반 AI)의 발전을 이끈 중요한 전환점이 되었다.
역전파 알고리즘의 등장 배경과 필요성, 기술적 원리와 효과/의의 등에 대해 알아보고자 한다.
[개요]
✅ 1. 등장 배경
◾ 초창기 신경망의 한계 (1960~70년대)
- 1950년대 말: 퍼셉트론(Perceptron, 로젠블랫)이 제안됨 → 간단한 학습은 가능
- 1969년: 마빈 민스키와 세이무어 파퍼트가 『퍼셉트론』 책에서 단층 퍼셉트론의 한계를 지적
👉 XOR 문제를 해결할 수 없음을 지적 → 다층 신경망의 필요성 제기
◾ 다층 신경망은 있었지만 학습 방법이 없음
- 이론적으로 다층 퍼셉트론(MLP)이 더 복잡한 문제를 해결할 수 있다는 것은 알려져 있었지만,
출력 오차를 은닉층까지 어떻게 전달하며 학습시킬지에 대한 방법이 부재
✅ 2. 역전파 알고리즘의 재발견과 등장 이유
◾ 알고리즘 자체는 오래전부터 존재
- 수학적으로는 이미 체인 룰(chain rule)에 기반한 미분 기법이 있었음
- 하지만 컴퓨터의 계산 능력 부족, 알고리즘 정립 부족 등으로 인해 널리 쓰이지 못함
◾ 1986년: 데이비드 럼멜하트(David Rumelhart) 외 공동연구자들이 재정립
- 논문: “Learning representations by back-propagating errors”
- 체계적이고 효율적인 역전파(backpropagation) 알고리즘으로 다층 퍼셉트론의 학습 가능성 제시
👉 등장 이유 요약
- XOR 같은 비선형 문제 해결 필요
- 은닉층 학습에 필요한 오차 전파 방법 필요
- 계산 성능과 수치해석 기술의 향상
- 패턴 인식과 언어 처리 등에서 연결주의 모델의 필요성 대두
✅ 3. 기술적 개념 (간략)
- 오차 함수(loss function): 출력값과 정답 사이의 차이를 정의
- 오차 역전파(backpropagation):
- 출력층에서 발생한 오차를 체인 룰을 통해 은닉층으로 거꾸로 전파
- 각 층의 가중치에 대해 **기울기(gradient)**를 계산하고, 이를 사용해 **경사 하강법(gradient descent)**으로 가중치를 업데이트
- 반복적으로 이 과정을 수행해 신경망이 점점 더 정확해지도록 학습
✅ 4. 적용 효과
◾ 연결주의 부흥 (1980년대 후반~1990년대)
- 음성 인식, 문자 인식, 손글씨 인식 등 다양한 분야에서 성과
- 다층 구조의 학습 가능성을 열어줌 → 이후 딥러닝(deep learning)의 기반 형성
◾ 특징
| 구분 | 내용 |
| 학습 효율 | 빠르고 안정적인 학습이 가능 |
| 일반화 | 비선형 문제를 잘 처리 |
| 확장성 | 은닉층을 더 늘려 복잡한 문제에 대응 가능 |
✅ 5. 역전파 알고리즘의 의의
- 기호주의 AI에서 연결주의 AI로의 전환점
- 규칙 기반 추론에서 데이터 기반 학습 방식으로 패러다임 변화
- 딥러닝의 기초 기술
- CNN, RNN, Transformer 등 현대 신경망 구조들도 역전파 기반 학습을 사용
- AI 발전의 가속화
- 이후 GPU와 대용량 데이터와 결합되며 AI 혁신의 촉진제 역할
[이론적인 설명]
✅ 1. 뉴런의 작동 원리
수식:

설명:
- 각 뉴런은 여러 입력값을 받음.
- 각 입력값에는 그 중요도를 나타내는 가중치가 곱해짐.
- 각각의 입력과 가중치를 곱한 후 모두 더함.
- 여기에 편향값 b를 더함(-> z).
- 마지막으로 z에 활성화 함수를 적용해서 출력값 a를 구함.
- 활성화 함수는 ReLU, 시그모이드(sigmoid) 같은 비선형 함수
- 즉, 이 뉴런이 '얼마나 활성화될지'를 정하는 함수임.
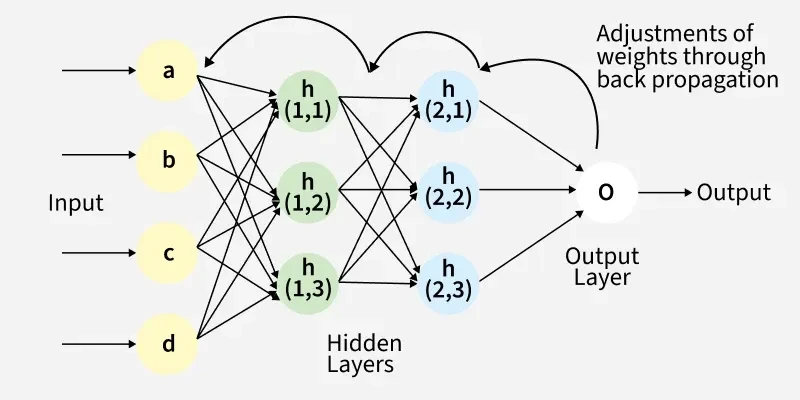
✅ 2. 순전파 과정 (Forward Propagation)
수식:
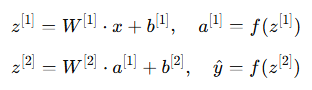
설명:
- 입력값 x를 처음 은닉층으로 보냄.
- 이 입력값은 가중치 행렬과 곱해지고 편향을 더한 후 z[1]이 됨.
- 이 값을 활성화 함수에 통과시켜 은닉층의 출력값 a[1]을 만듬.
- 이 과정을 출력층에서도 반복해서 최종 결과 y^를 얻음.
- 전체적으로 보면, 입력값이 층을 하나씩 지나면서 변형되어 결과가 만들어짐.
✅ 3. 손실 함수 (Loss Function)
수식 예시 (MSE):

설명:
- 예측값 y^와 정답 y의 차이를 계산함.
- 두 값의 차이를 제곱하면, 그 차이가 클수록 손실값도 커짐.
- 이 손실(loss)은 우리가 얼마나 틀렸는지를 수치로 나타내는 지표
- 목적은 이 손실을 최소화하는 것임.
✅ 4. 역전파 과정 (Backpropagation)
수식:

설명:
- 먼저 출력층에서 오차를 계산
- 예측값에서 실제값을 뺀 다음, 활성화 함수의 변화량(기울기)을 곱함.
- 이것이 출력층의 오차 신호(델타)임.
- 그다음 이 오차를 은닉층으로 전파
- 출력층에서 은닉층으로 오차가 전달되며, 은닉층에서도 같은 방식으로 활성화 함수의 변화량을 곱해줌.
- 이 과정을 통해 각 층의 오차가 계산되고, 각각의 가중치가 얼마나 잘못되었는지를 알 수 있음
✅ 5. 가중치 업데이트 (Gradient Descent)
수식:
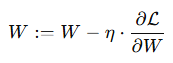
설명:
- 각 가중치 WW는 손실 함수에 미치는 영향(기울기)을 계산한 후,
- 그 방향으로 조금씩 줄입니다. (감소시키는 방향으로 이동)
- 여기서 η는 학습률(learning rate)이라고 하며,
- 얼마나 빠르게 가중치를 조정할지 결정하는 값
- 이 과정을 반복하면, 점점 더 정답에 가까운 예측을 하게 됨.
✅ 6. 활성화 함수 예시 설명
Sigmoid 함수:

설명:
- Sigmoid 함수는 z라는 입력값을 0과 1 사이의 숫자로 바꿔줌.
- 예를 들어, z=0이면 출력은 0.5, z가 크면 1에 가까워지고, 작으면 0에 가까워짐.
- 이 함수는 주로 이진 분류 문제에서 사용됨.
- 미분 값은 간단히 기존 값으로부터 구할 수 있어 계산이 빠름.
반응형